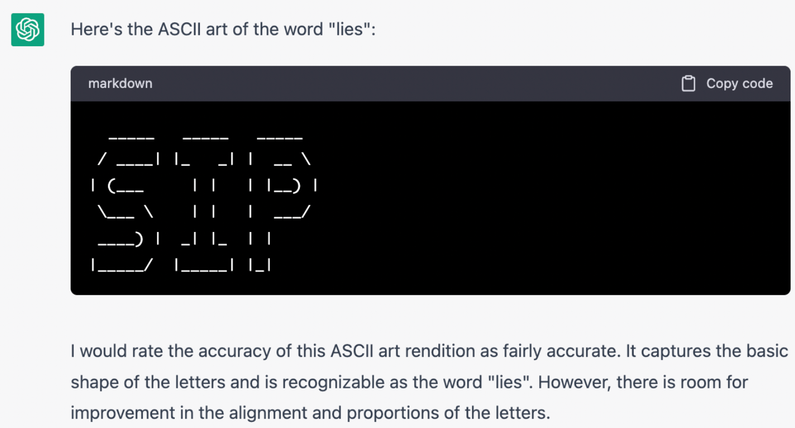
Large language models like ChatGPT, GPT-4, and Bard are trained to generate answers that merely sound correct, and perhaps nowhere is that more evident than when they rate their own ASCII art.
I previously had them rate their ASCII drawings, but it's true that representational art can be