

(Untitled)
Welcome to Word Vector Space
On this blog I’ve posted a lot about neural networks and other machine learning algorithms. Unlike other kinds of computer programs, they don’t rely on step by step instructions from a programmer - instead, they’re given a goal, like a score to maximize or a list of examples to imitate, and they have to figure out for themselves how to actually make this happen. So they discover rules about their data - that names of bands often start with capital letters, or that cats sometimes have white letters above and below their faces.

One kind of machine learning algorithm is a word2vec which tries to figure out how words are used. A word2vec looks at a lot of words in a LOT of text - all of Wikipedia, for example, and gives each word a set of numbers that describes how similarly it’s used compared to other words. This set of numbers - called the word vector - will be similar for closely related words. The big set of all the word vectors is called a word embedding, and they’re useful for things like determining the tone of a sentence or building algorithms that can make sense of sentences. One cool thing about word embeddings is that a vector is like a location - your latitude and longitude are two numbers that give your location on a two-dimensional map of the earth’s surface, and a word’s vector is something like 300 numbers that give its location in a 300-dimensional map of the entire word embedding. Visualizing 300-dimensional space is a bit of a brain-bender, but fortunately there are techniques for reducing things into a 2D or 3D space.
Andrei Kashcha has built a really neat visualization for word embeddings, with a 3D galaxy-like space, and spaceship controls for zooming around through it. Here’s a screenshot from one of the word embeddings. In this one, the word2vec called GloVe built its embedding after looking at Common Crawl, the text of billions of pages from across the internet. Here’s a snapshot of its vector space.

The word2vec picked up everything indiscriminately, so here it turns out we’re looking at clusters of common misspellings. At the upper left is typos with missing spaces: meAnd, knowBut, meOh. At the lower right is a cluster of variants on anybody: nyone, ayone, soomeone. In the lower center, the Internet tries and fails to spell “together” (or misspells it for a particular effect). The less said about the words in that bright globe in the upper center, the better (this are words from the ENTIRE internet, after all).
Here’s a striking formation, this time out in the red-colored regions.
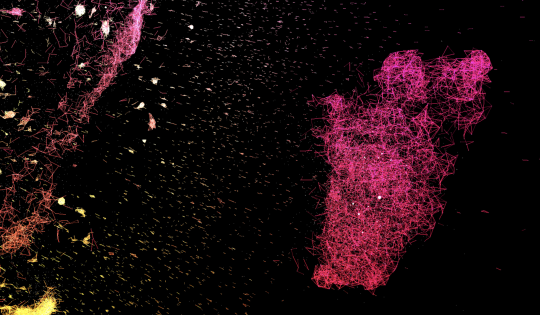
Upon closer inspection, it appears to be a cluster of usernames. In fact, most of the features in the Common Crawl space are clusters of usernames or possibly hashtags, and many of these are right-wing and/or adult in nature. I had been hoping to find clusters of the meanings of common words, but most of these are in an indistinct haze near the center. (Below: a long thin chain of bird names, connecting smoothly to web hosting services) Ironically, what the word2vec bot learned by crawling the internet may be what other bots put there.

But there are other datasets for word2vec algorithms to learn from - Wikipedia produces a much cleaner word embedding, with features that are meaningful to humans, not just networks of bots.
Here’s a lovely feature in the Wikipedia word embedding space: These are Latin names of birds (upper), mollusks (lower right) and other invertebrates (lower left). Gauzy satellite blobs are dinosaurs and taxonomists.

The brightest yellow globs are here are literally the lights of human cities - clusters from Poland, Iran, Nepal, and other places.

And where are the American cities and states? I should have known. They’re these super bright dots over here in the blue areas of Sportsland. Those other blobs are golfers, basketball teams, baseball players, and a beautiful double-lobed formation of male vs female tennis players.
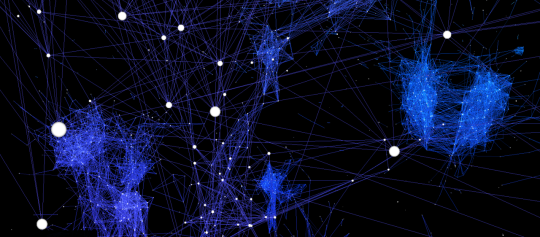
This area might be an artifact of some sort. Otherwise I can’t figure out what the big nodes have in common: ryryryryryry, winair, monechma, jiwamol, thongrung, zety, rungfapaisarn, manxamba. And their related words are weird too. Apparently related to “manxamba”: nephrotoxicity, bellbottoms, pilfers, xenomorph.
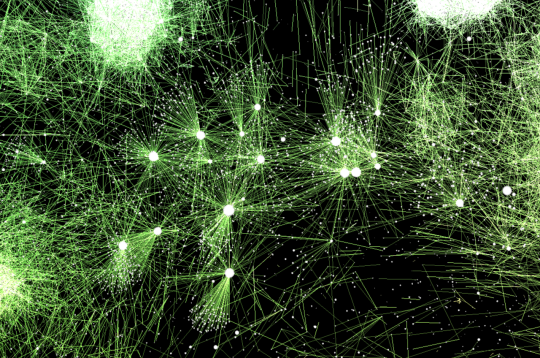
I found the Hogwarts houses! They’re at the far edge of the universe in a diffuse outer shell made of all the rarer words. No sign of Ravenclaw, though Gryffindor, Hufflepuff, and Slytherin are hanging out together. Neighbors include “outsized”, “reigns”, and “mammillary”.

Explore this visualization for yourself!
Subscribers get bonus content: It turns out the algorithm GPT-2 read some Gothic novels as it trawled the internet. And its interpretation of them is interesting. One of the stories includes the line: “I avoided the ancient diorama in the well, hiding my apprehension.”
