I generally am uninterested in generative AI that's too close to the real thing. But every once in a while there's a modern AI thing that's so glitchy and broken that it's strangely compelling. There's this generative AI knockoff of Minecraft that fails so hard at being Minecraft that it becomes something else.
Trained on Minecraft with its huge randomly-generated landscape of punchable blocks, Oasis Minecraft will let you walk around.
But there's no object permanence. Look at a mountain, look away, and look back at it, and the mountain's completely gone.
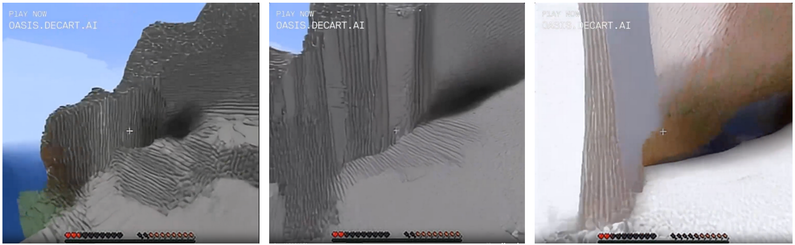
I found myself in this wooden cavern (which I did not build; I just came across it like a natural formation):
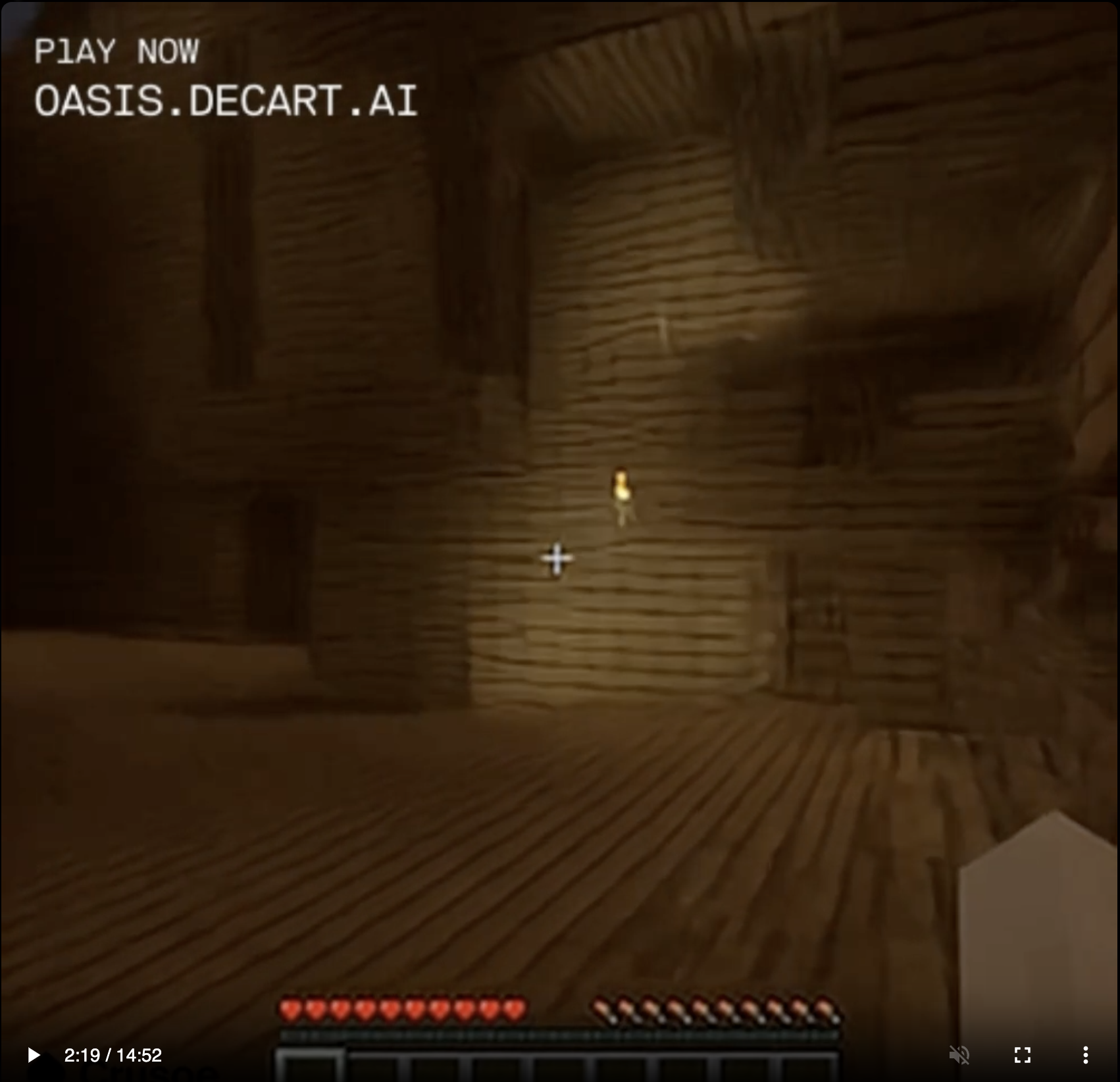
I walked up to the wall, backed up, and now I was here against the side of a mountain instead.
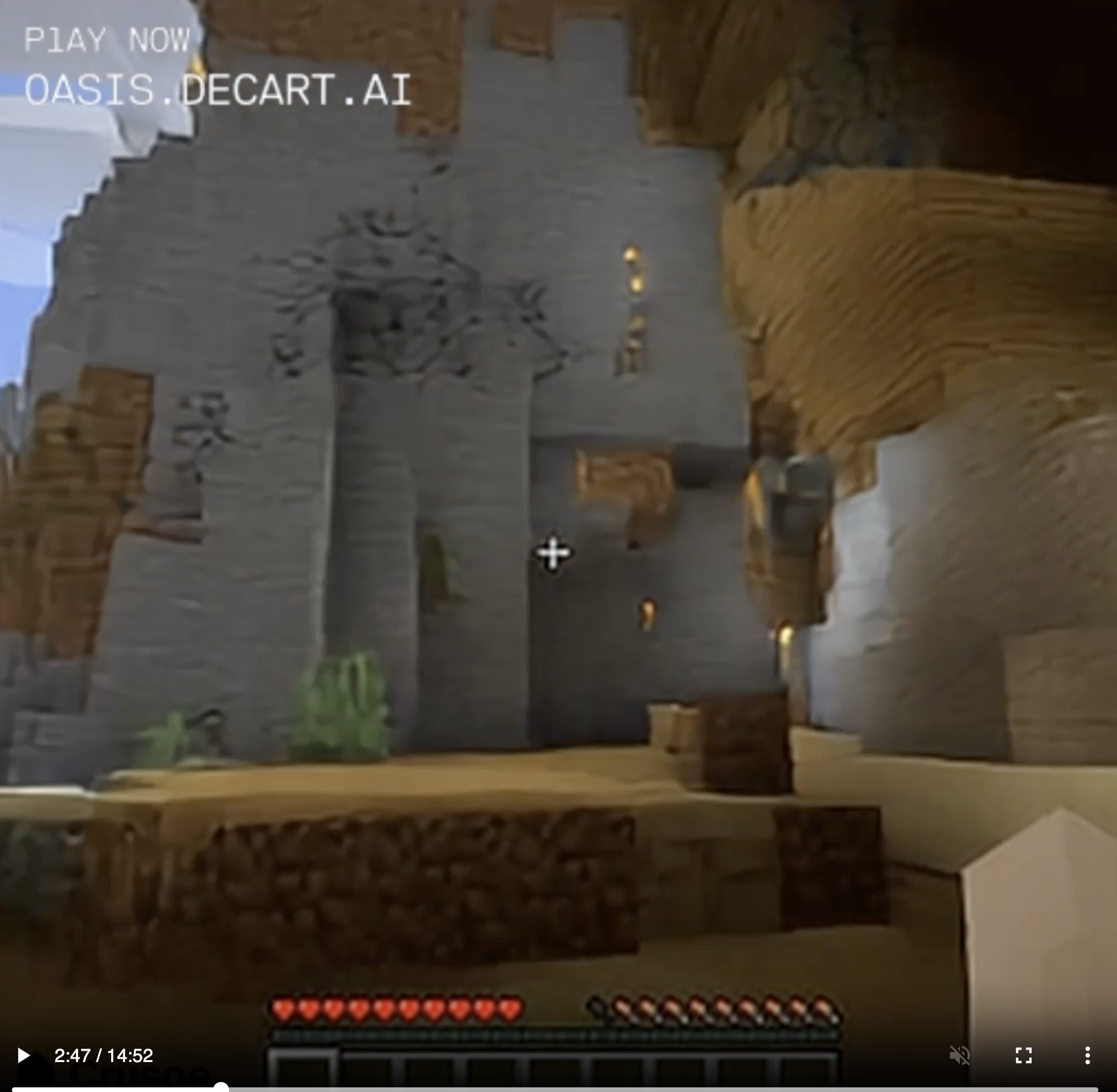
Build a structure, fail to maintain it in direct view at all times, and it's gone the next time you look around.
The program was trained to predict the next frame of a game of Minecraft based on what appears to be a combination of the previous frame and whatever commands the user is sending. There's no underlying physics engine, no library of standard block or creature types and their properties, which means that things like half blocks and quarter blocks can exist. You can dig a hole exactly wide enough for yourself and then fail to fall into it, no matter how much you jump up and down over the opening. The blocks in the landscape are only approximations, and if you approach them they seem to shift and morph, attempting to look casual. I walked toward the torchlit area in the screenshot above, and there was a point at which the torchlit "stone" got too bright and texture-y, so it morphed into birch tree bark.
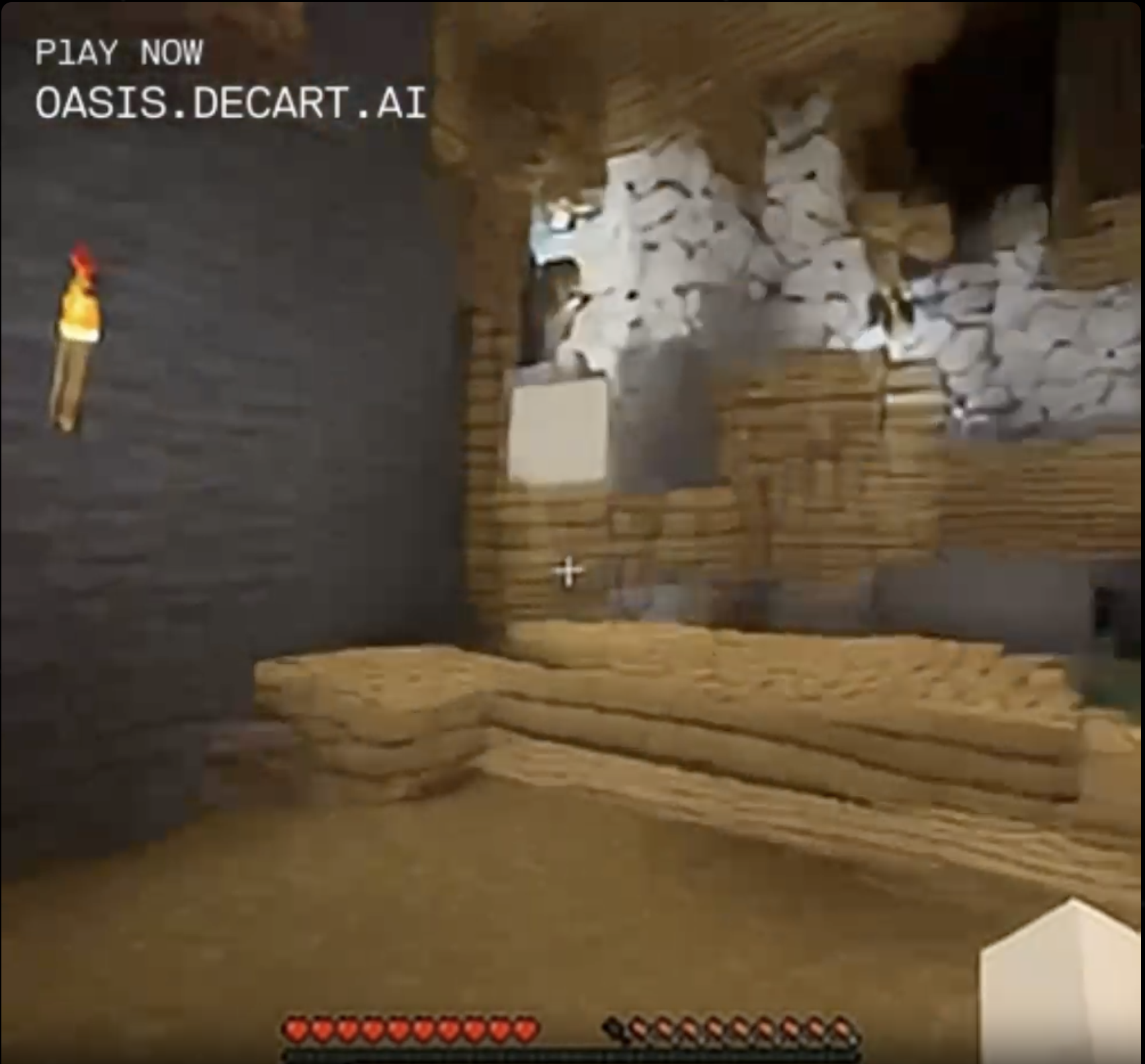
I managed to get a pretty good look at it trying to be birch tree bark in a wooden cave. Improbable, but it was going to try to go with that.
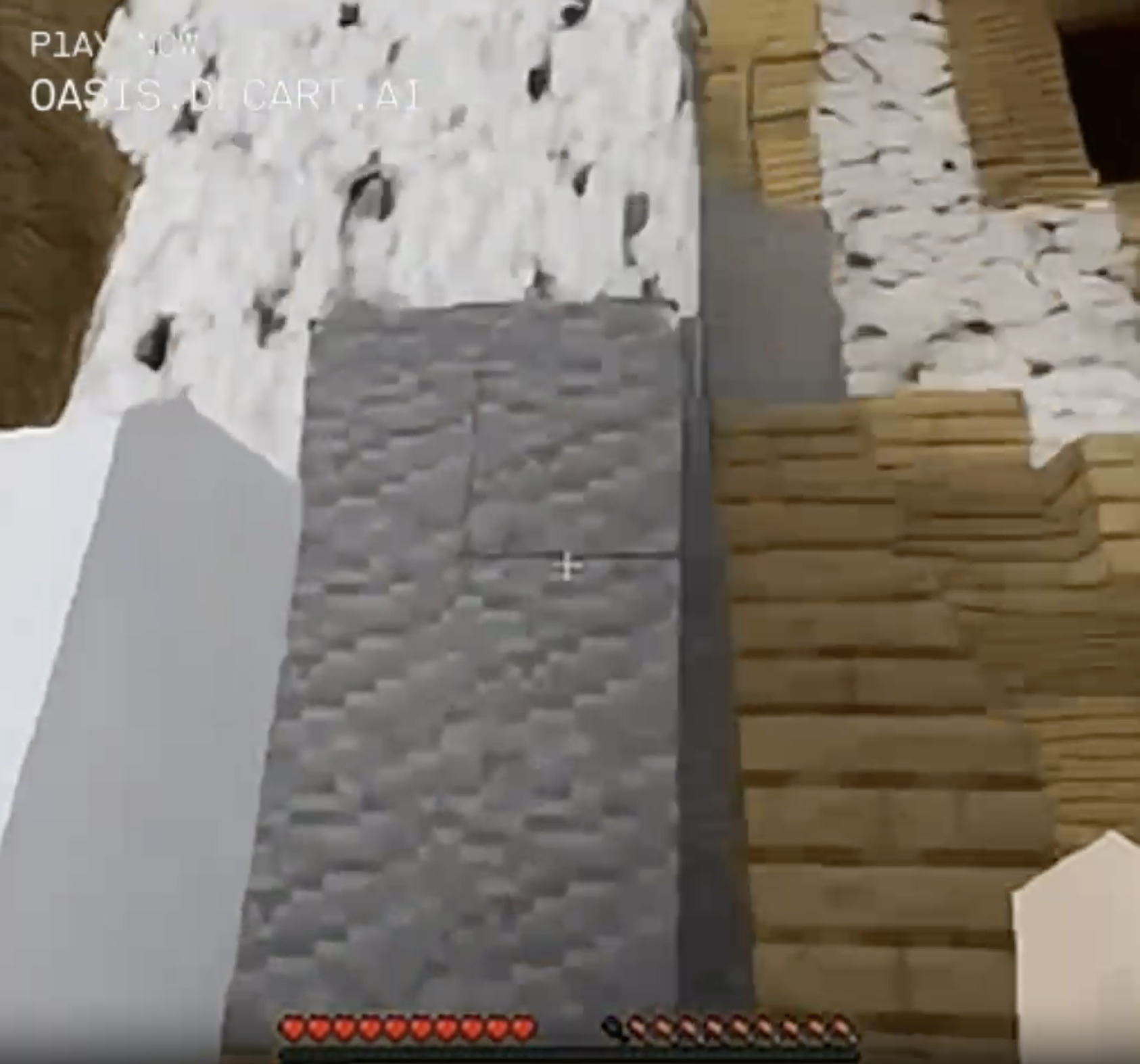
Then I looked up too closely and steeply at the birch bark, losing track of the surrounding cave, and in a couple of chaotic frames...

The birch bark wall became snowy floor.

No wait, desert.
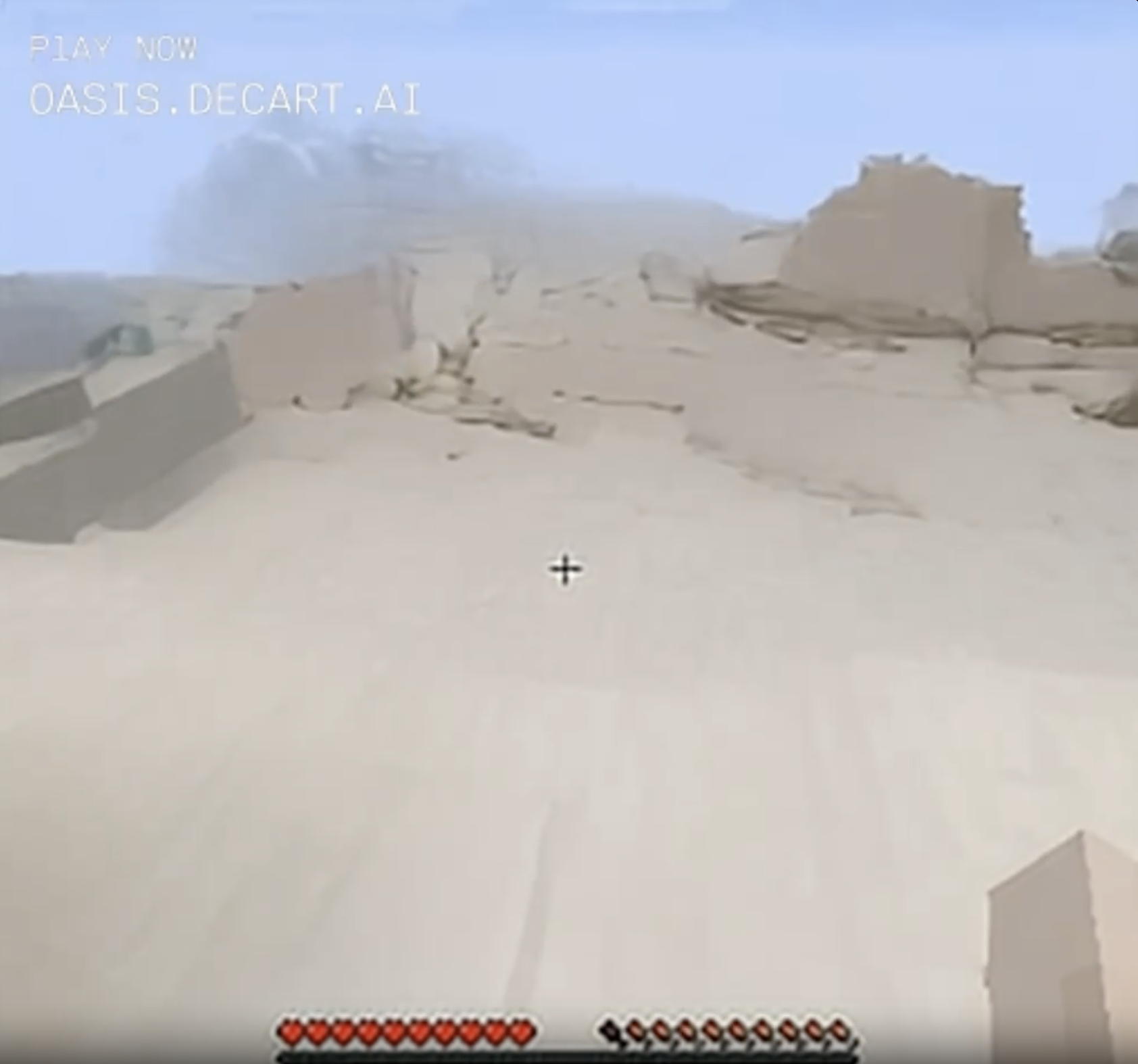
Liked that natural wooden cavern? Too bad, it's gone forever. You live in the desert now.
You can sometimes catch glimpses of rare blocks, like lava or pigs, but they tend to turn into ordinary dirt or sand when you approach.
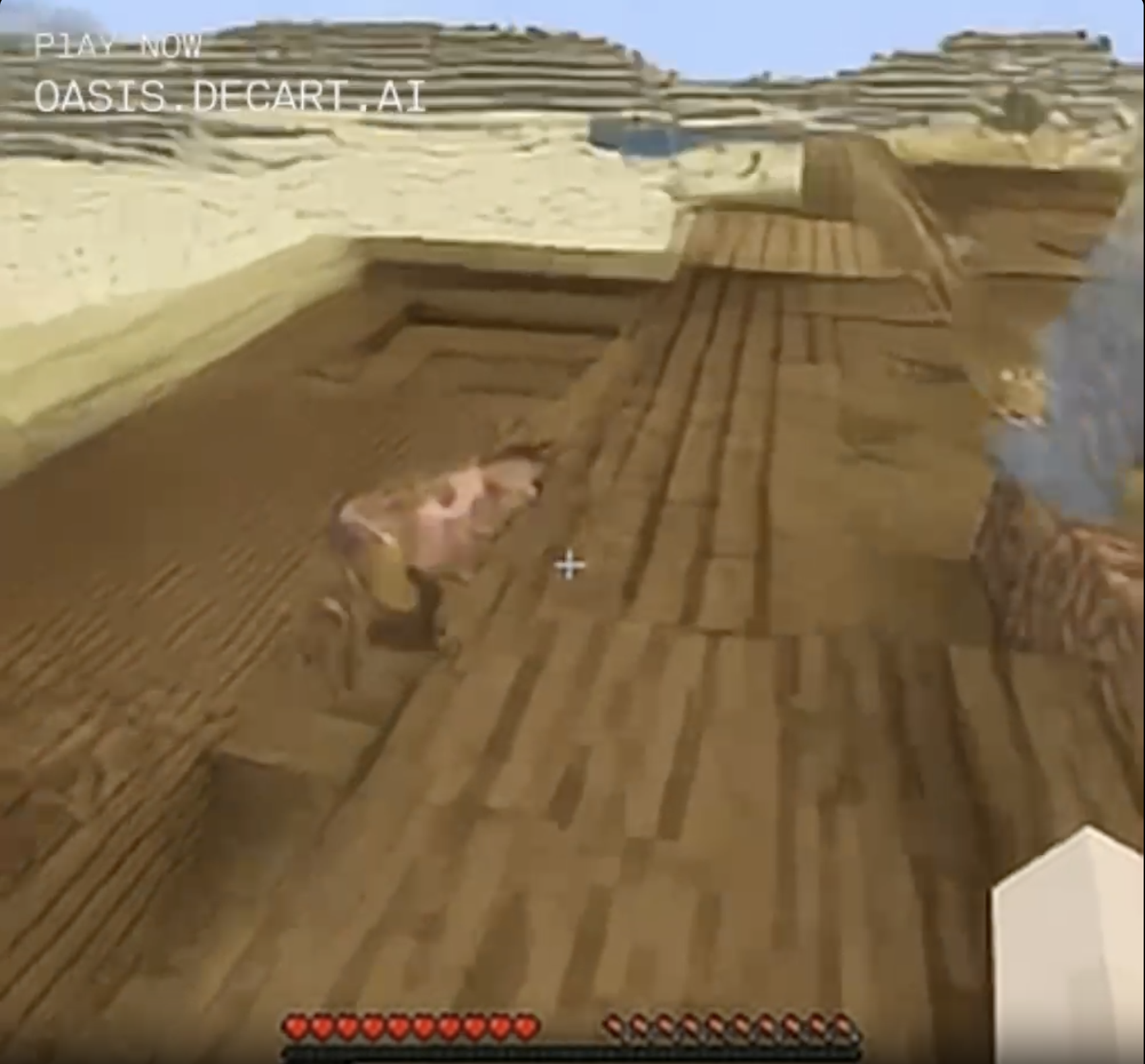
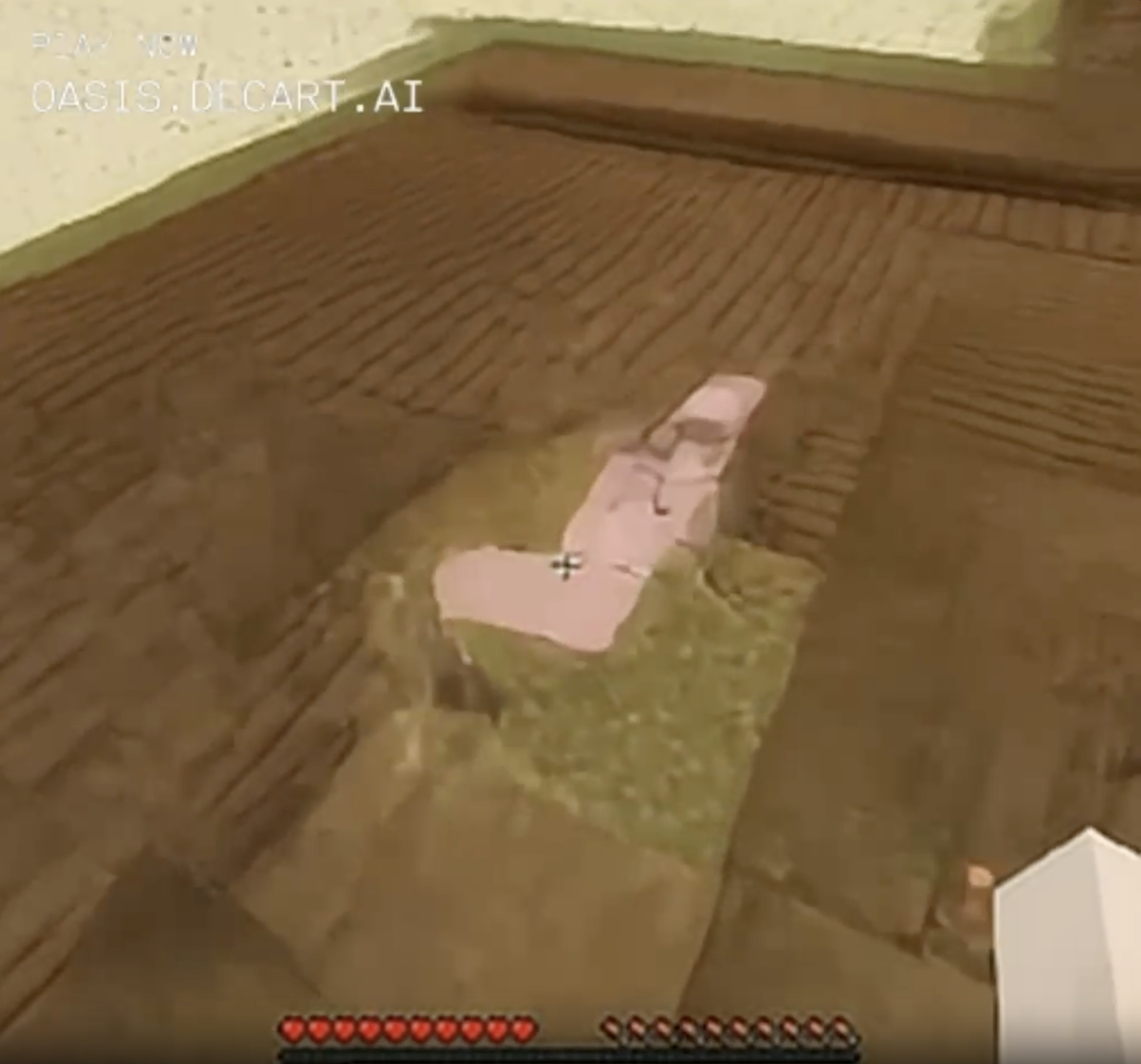
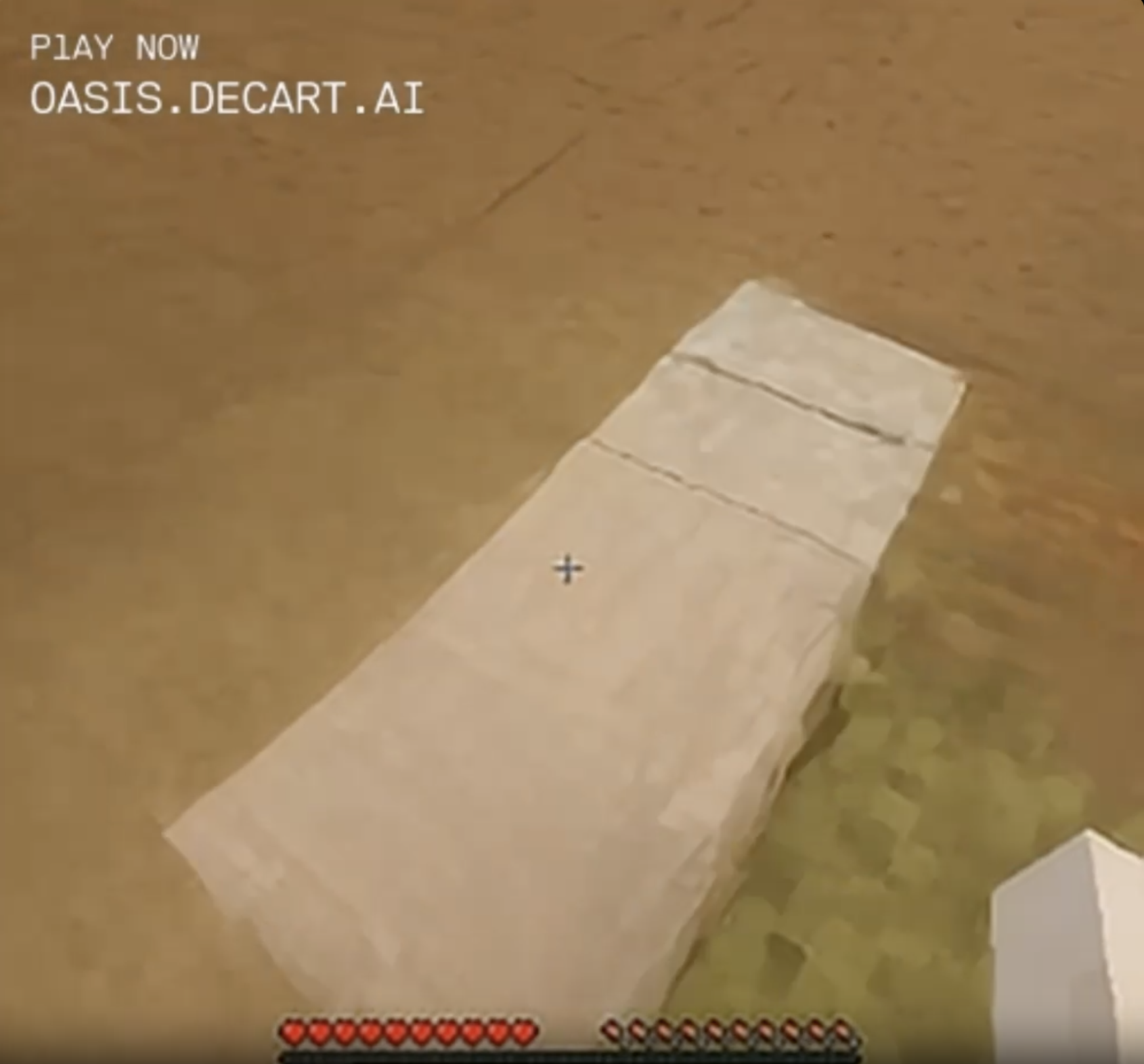
What's that pink patch of pixels in the middle of the weird wooden floor in the desert? Approaching closer, it's even pinker and weirder - could this be a rare glimpse of a minecraft animal? It's uh, j-shaped? Determined to walk closer and not let it out of my sight until it reveals its secrets. Annnnd it's.... sand.
On the other hand, if you stare fixedly at ordinary blocks and approach them, they tend to get weird. Noise in a generative algorithm usually comes in the form of strong striped patterns, so by continually staring in the same direction you force the "Minecraft" algorithm to keep generating new frames based on accumulating noise. A somewhat ordinary stone cliff face gradually loses what definition it has, becoming blocky and flat as it seems to panic.
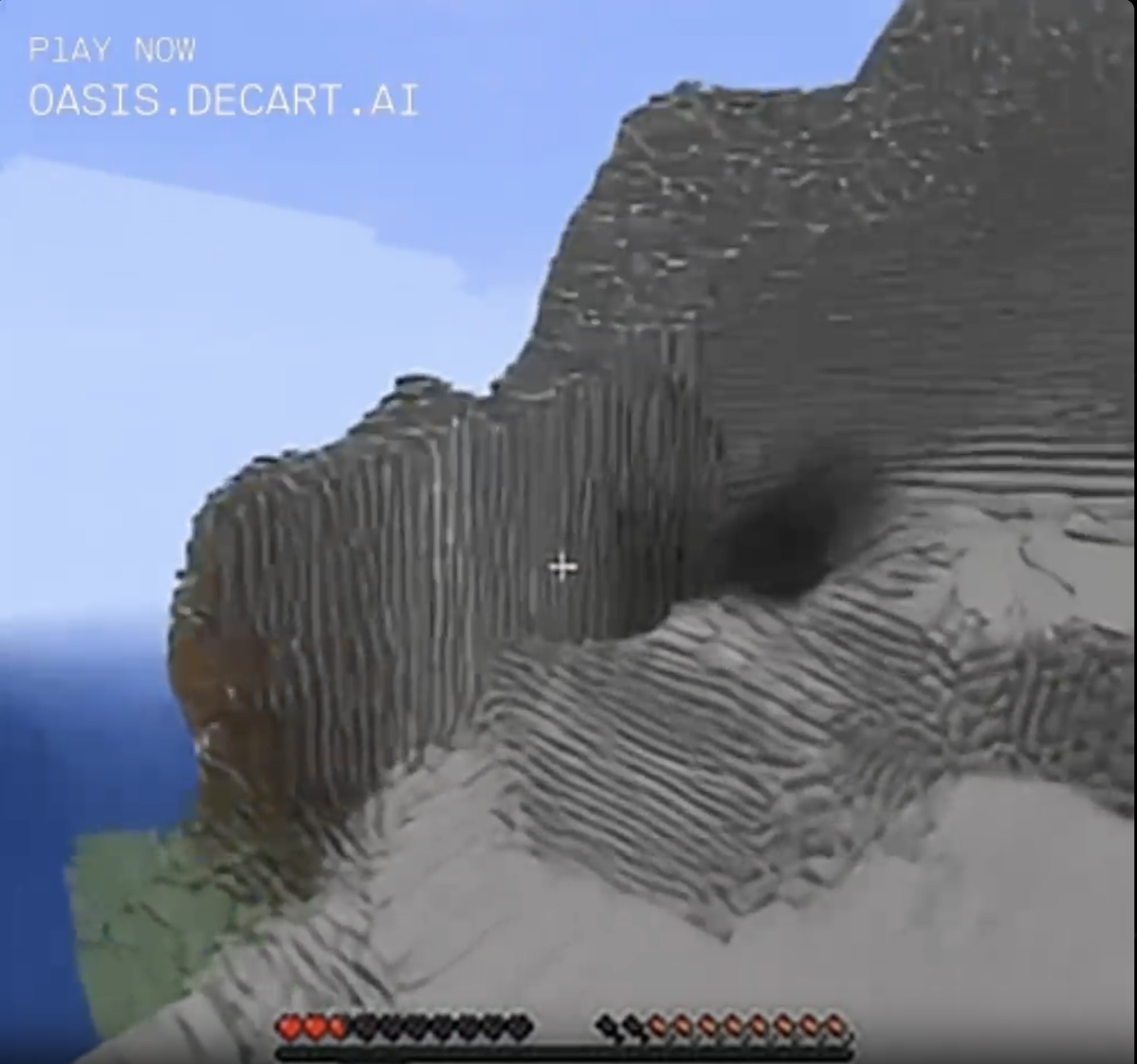
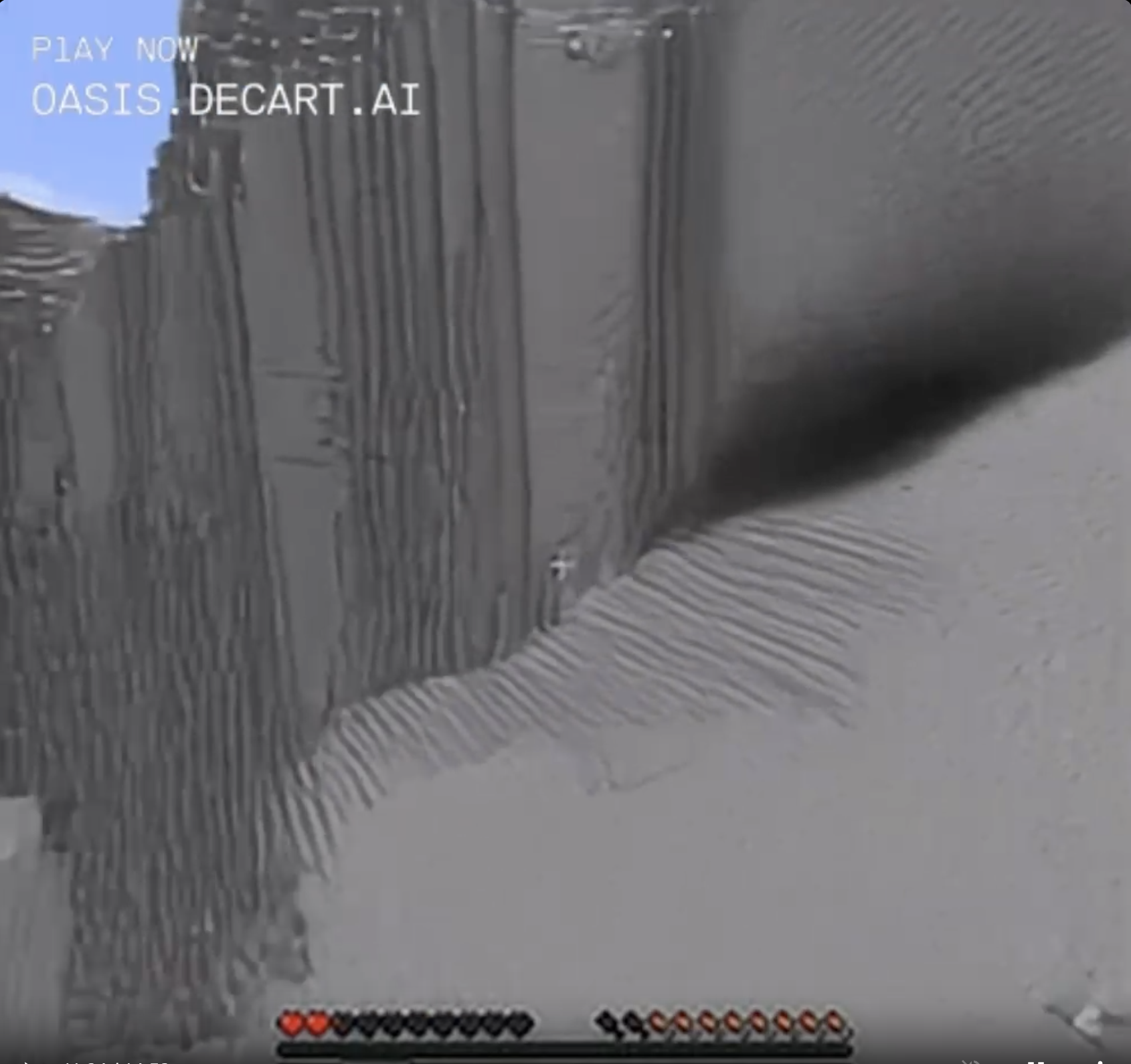

A natural cave turns in three frames from a sort of plausible looking feature in the side of a mountainside, to a weirdly smooth shadow on an ill-defined crease in the landscape. In the final frame the cave has turned a bit orange and the surrounding blocks have turned into blocks of shadowless grey and white that are impossible to interpret as any kind of 3D landscape. Also my hunger bar is rapidly decreasing for some reason, and my health is going down. The next several frames were extremely hard-to-interpret blocky chaos, but eventually I popped out into an ordinary desert.
At another point, I jumped into this ordinary bush, which became a deep, dark forest.
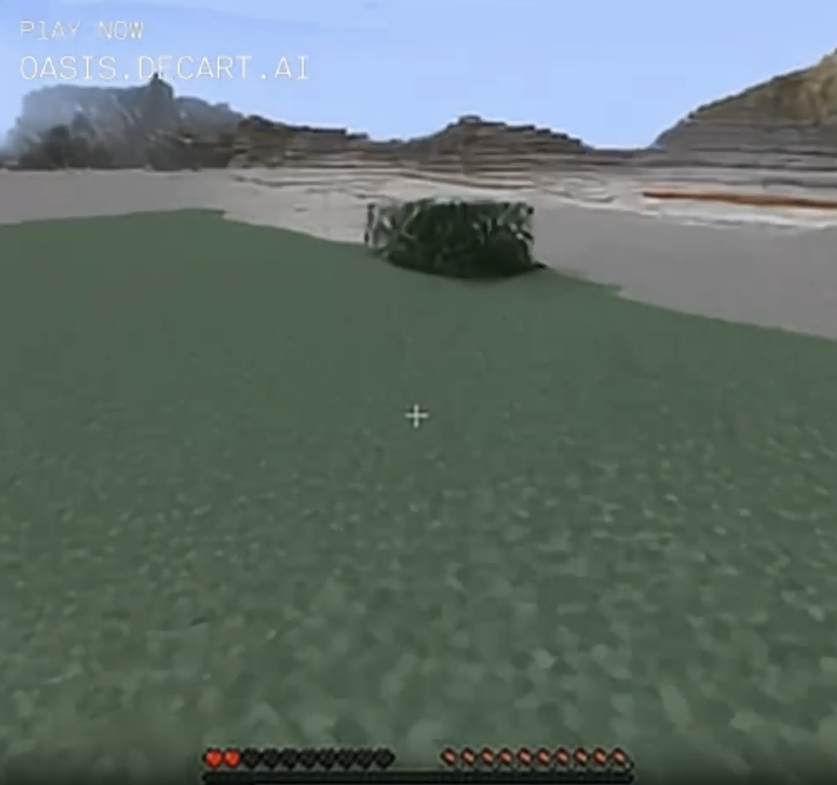
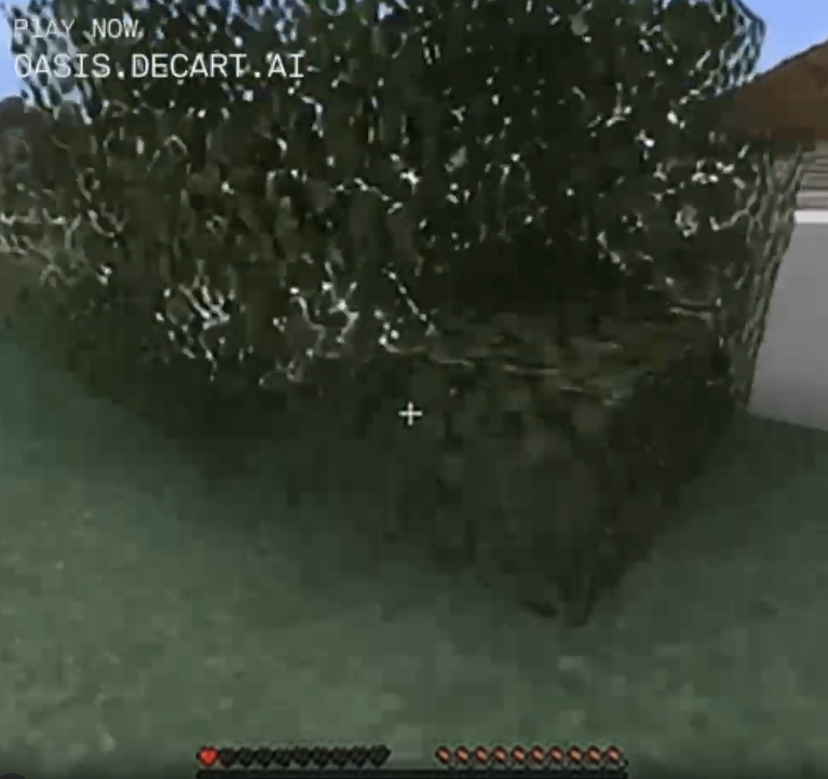
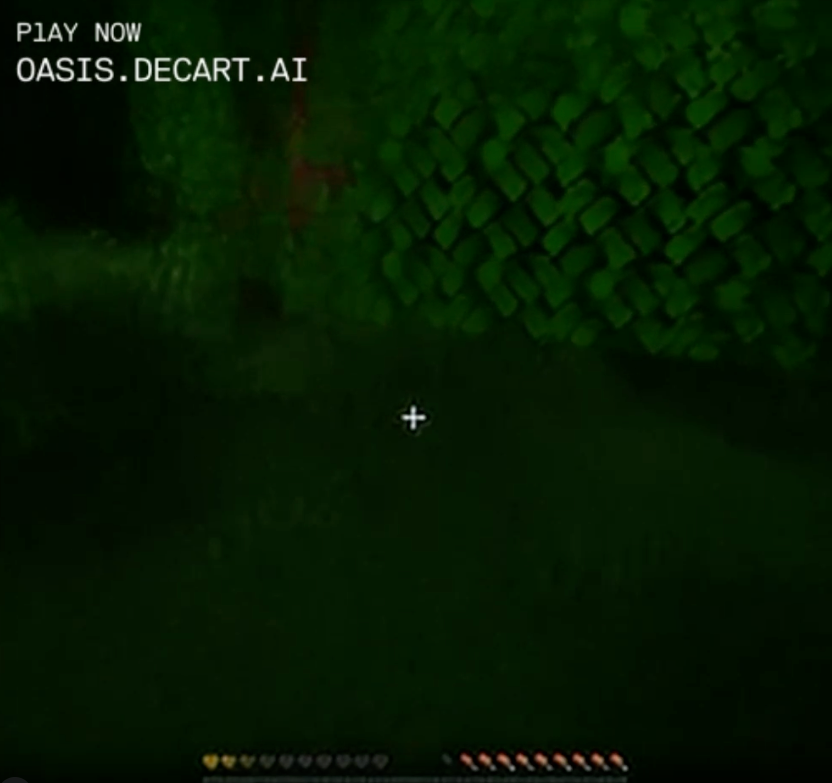
Note that the tiny bush on the left is about two blocks wide, then becomes a clump of about 20 bush-blocks as I get closer, then morphs into a lush forest with deep green leaves and thick trunks. Also my health bar turned from red to yellow for some reason? I'm sure it's fine.
I've made it a goal to see how completely I can get the generated landscape to freak out. One time I was swimming across a lake and noticed that the reflections at the water's edge were looking weirdly spiky.
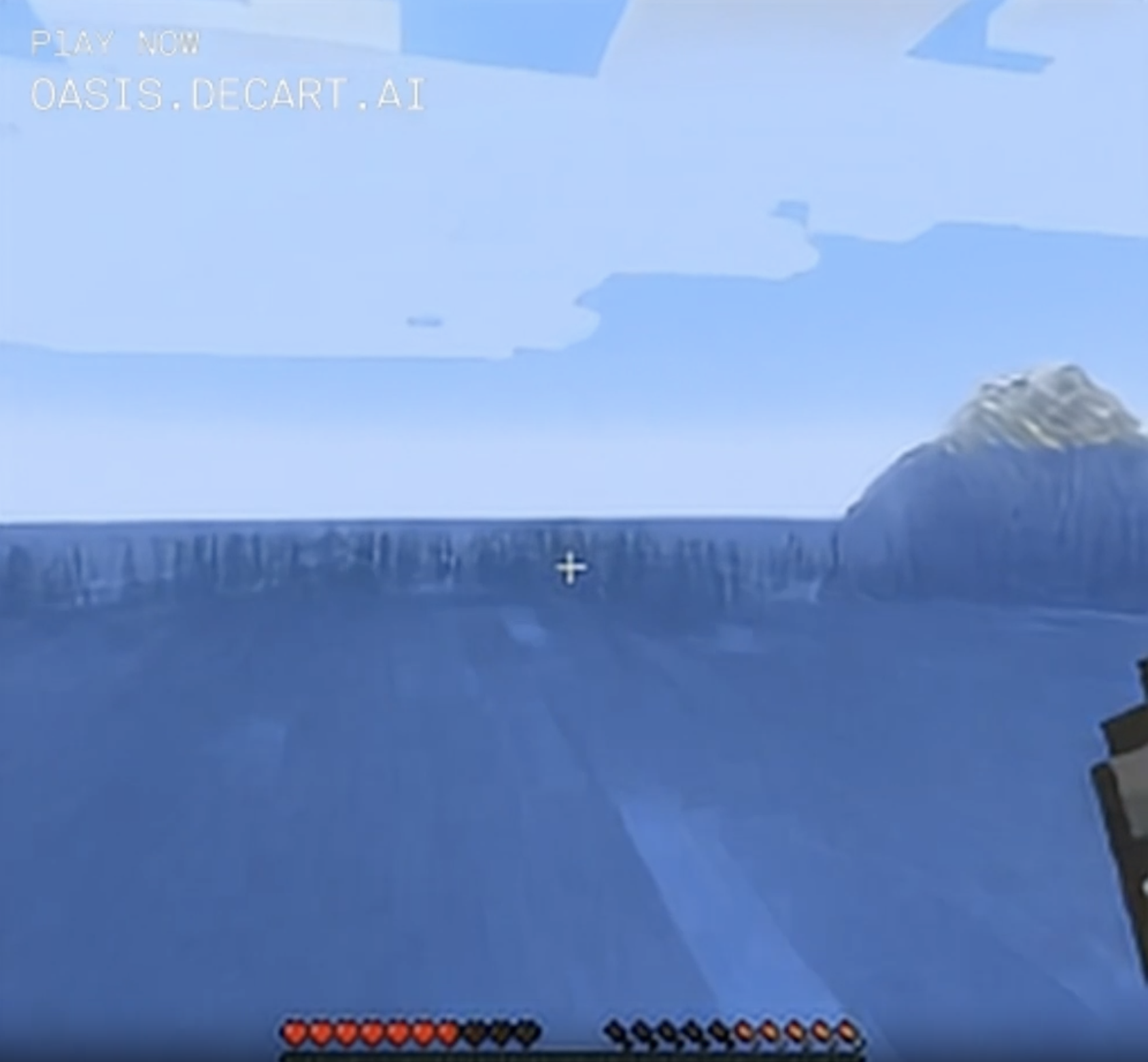
Swimming closer to them, they started to get even more strongly striped. Was this still supposed to be the horizon? Why did the rest of the water turn featureless? Why did the snowy mountain turn into trees? Was I even above water any more?
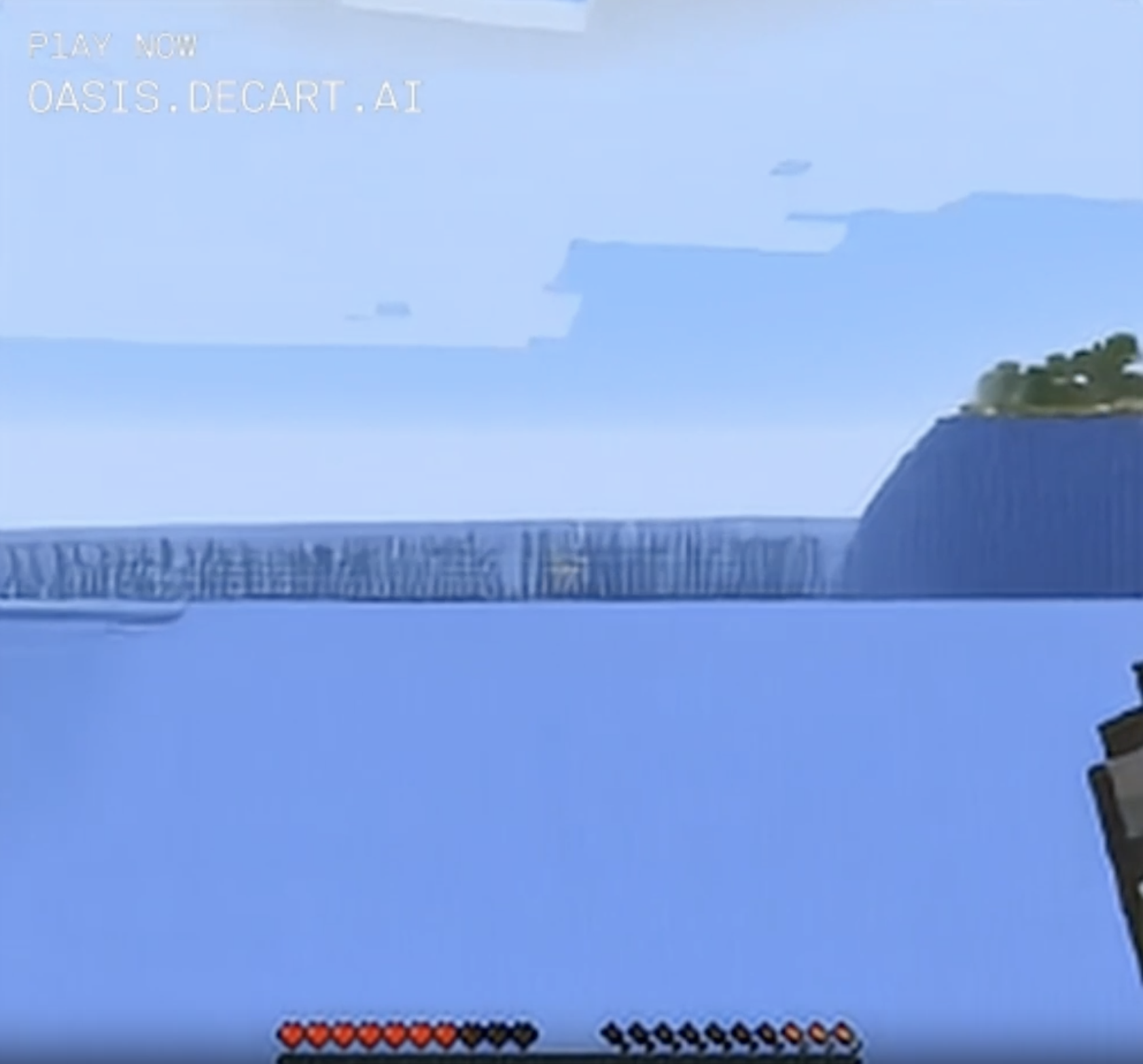
I swam closer and the water's edge became a weird static wall that engulfed the sun.
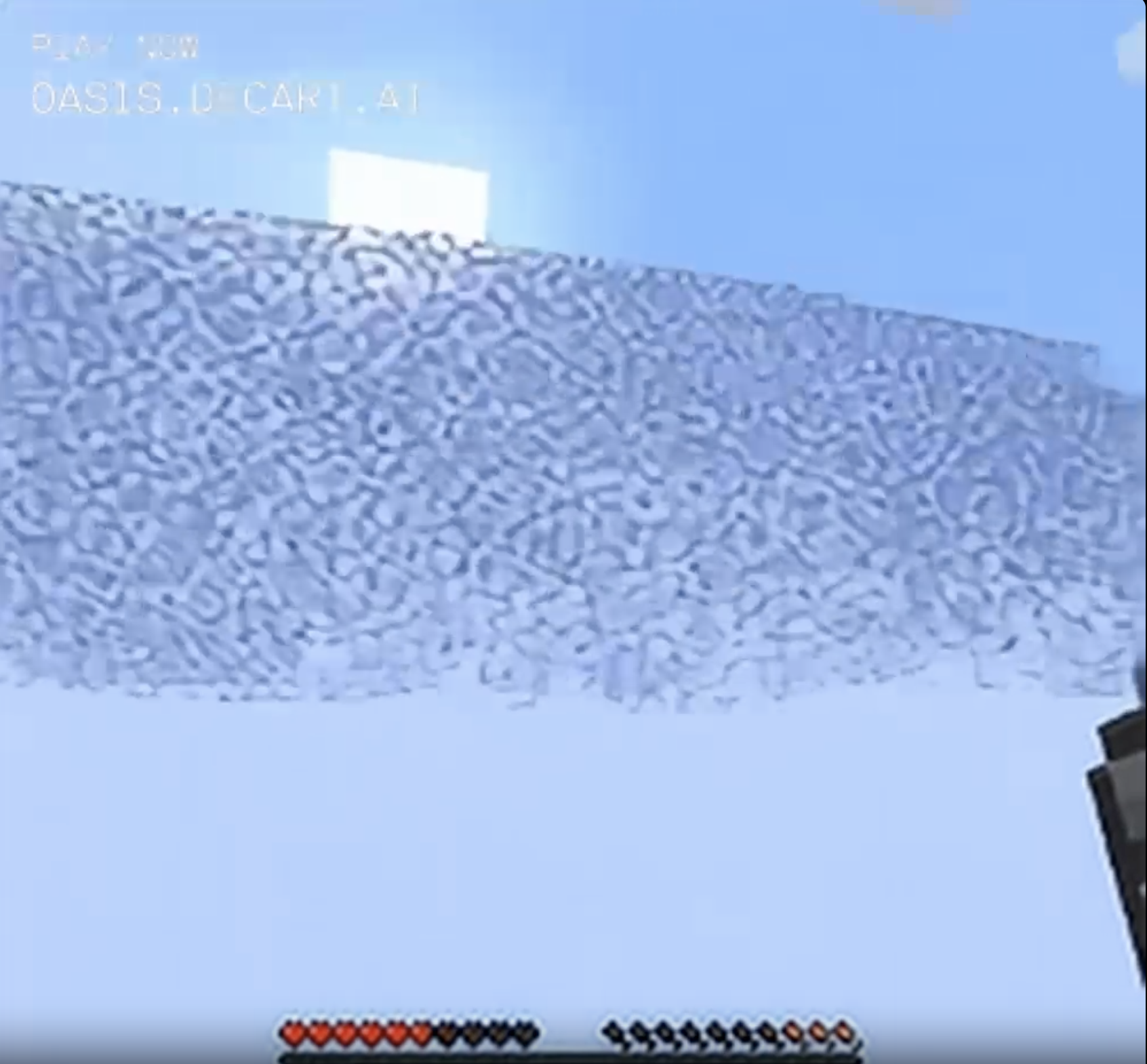
Then there was rather a lot of static for a while.

I wondered if I would be stuck here forever, but the static calmed into something that looked like snow. The AI even hopefully outlined a block as if it was something real that I might be able to dig into.

When I looked up from the snowy floor, I was in a weird cave filled with desert plants.

I thought at this point I would be back to normal gameplay, but something about this landscape was still incredibly unstable and shortly I was looking at two suns through yellow and green jell-o?

Things were very blocky and bright for several seconds but eventually resolved themselves into an ordinary desert landscape.
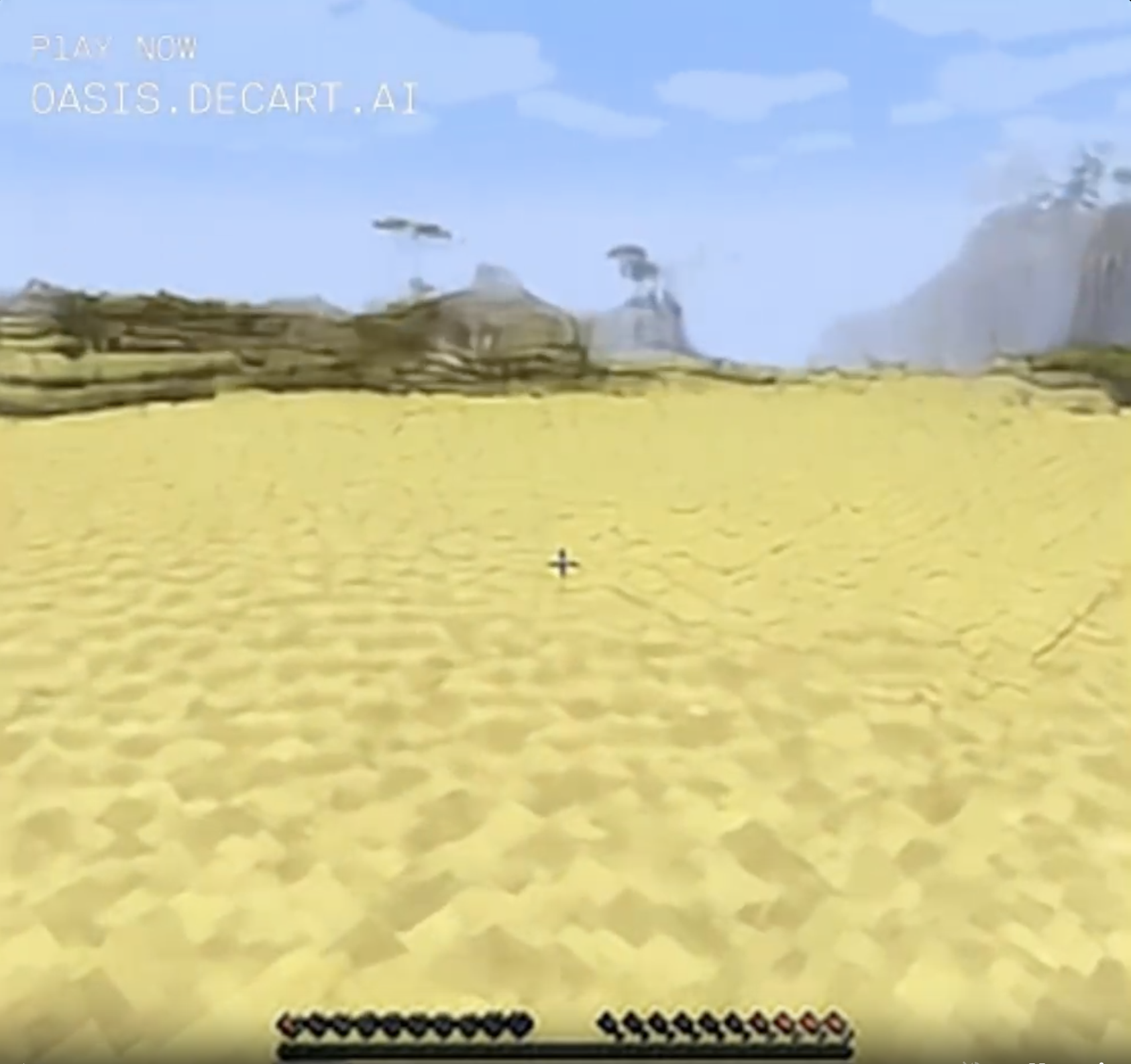
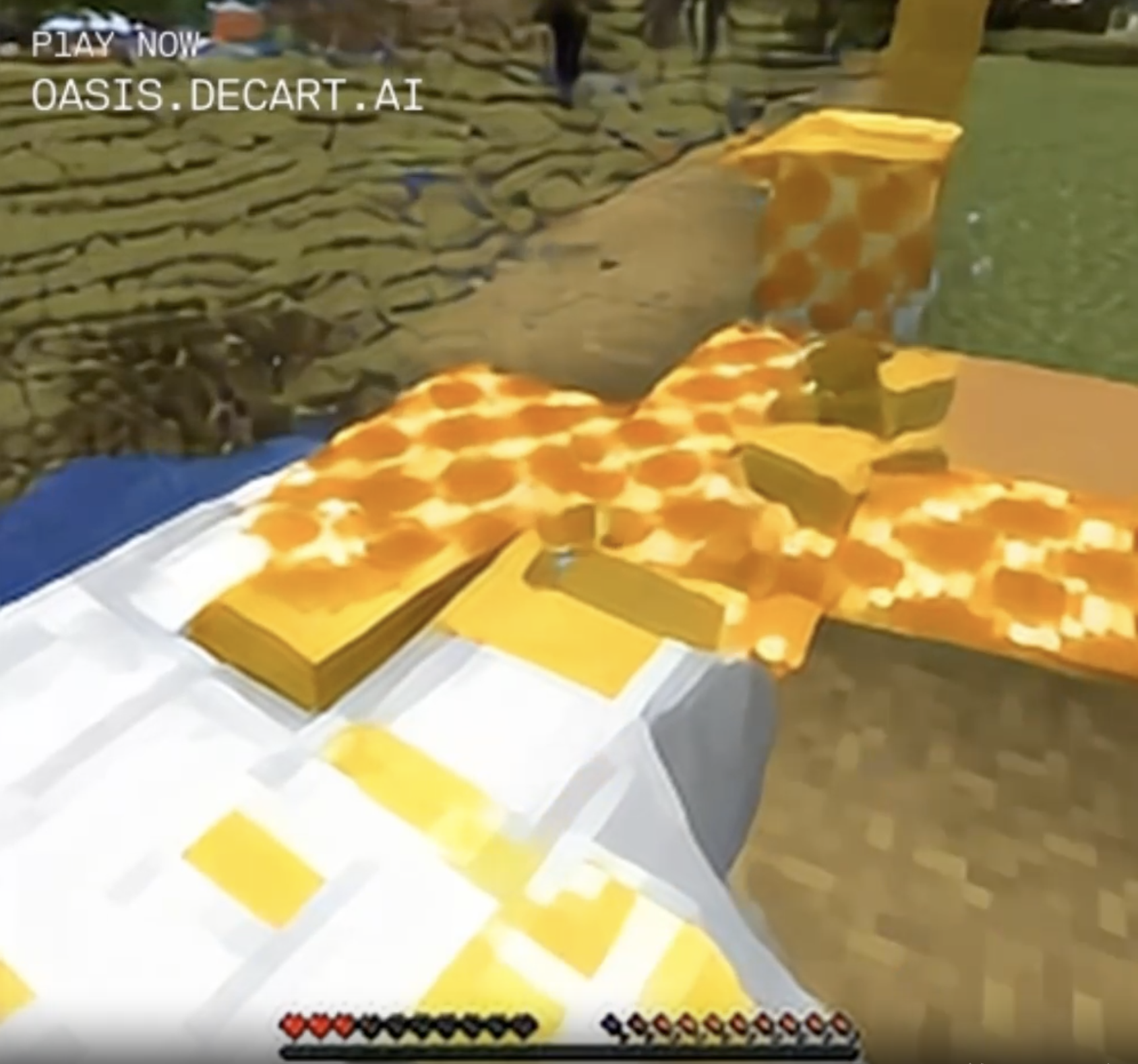
Chaos persisted, in the form of the desert frequently turning into natural blocks of rare glowstone. If I'd stared at them for long enough and let them fill my field of view, I likely would have ended up in the glowstone-paved Nether zone of Minecraft. (Unless that's a new cheese block? I haven't played Minecraft in a while, maybe they added cheese.)
I never died, though, despite my health bar going down to basically zero during my journey into the land of yellow jell-o. I don't think anything I do has any effect on my actual health - I think the AI just generally predicts that health sometimes goes up or down a little between gameplay frames, and that it goes down faster when you're in the presence of things that are generally flame-colored. Occasionally an apple or a carrot would appear in my inventory, but attempting to eat them didn't affect my health levels.
I did have an inventory the entire time, although I cropped it out in the above screenshots because they were masked by the controls every time I paused playback. The inventory never made sense. It was mostly empty, except for when the occasional pickaxe or chunk of dirt appeared there for a while. If I tried to use a pickaxe, it might appear in my hand for a few strokes and then apparently wander off again. Less identifiable stuff would appear in my inventory too, which never seemed to do anything when I tried to use it.
I tried to place a crafting table, but only got half-readable text saying "crafting table". The regular Minecraft game uses a message like this to announce your success at making a crafting table the first time you manage it - this usually happens early enough in the Minecraft game that it probably came up a lot in training. Occasionally AI Minecraft will give me other messages in the same white text, but they're even harder to interpret.
Anyways, instead of a crafting table, I got this stick instead. Thanks, AI Minecraft.
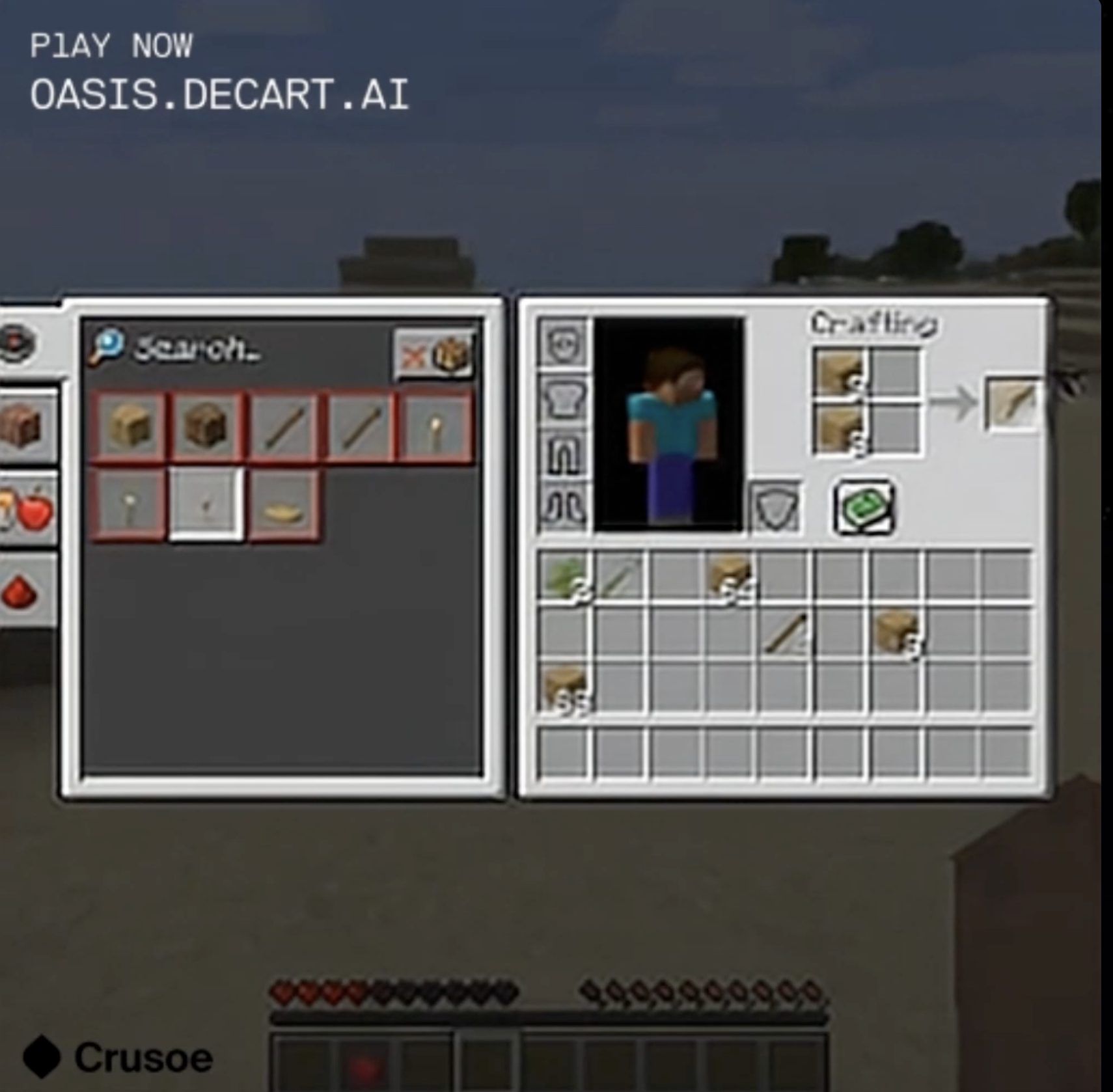
The general inventory-checking command works, and even comes with an apparent crafting table setup (even if I'm nowhere near a crafting table). Most of the inventory is unidentifiable and ununsable, so I couldn't get anything I did on this screen to have an effect on the items I had access to when playing in the map. By the time I gave up checking my inventory, I ended up with less in my ready inventory than when I had started.
So, nothing I collect stays with me, but on the other hand, nothing I build stays with me either. If I want to build a structure I'm better off staring at a mountain until the stones resolve into a wooden wall. If I manage to build or accomplish anything at all, I can't take my eyes off it or it will immediately disappear. This makes it pretty much impossible to make any progress in the game. The game loads with a list of "goals" beside the gameplay window, but as far as I can tell, there's no way to make these happen on purpose, nor does the game itself know when you've achieved them.

On the other hand, I was extremely excited to have somehow found myself in a glitchy realm made entirely of hay bales and green jell-o. For a while my unofficial goal has been to observe as many types of glitches as I can.
The team who trained the Oasis Minecraft generative AI call it "the first step in our research towards more complex interactive worlds." In their technical report they mention most of the glitches I've pointed out, and say that they would probably be improved with a larger model and more training data.
The problem, as far as I can tell, is that if all this works perfectly, this will be simply the human-programmed Minecraft we already have, except far more expensive to run. The original Minecraft is already infinitely playable, thanks to the way it randomly generates a 7x-larger-than-planet-Earth landscape with each new game. You can't use generative AI like this to get a new kind of game, only a better simulation of the game you trained it on.
I wonder if this glitchy, dreamlike landscape is already as good as it gets. It reminds me of my first time playing an early AI-generated imitation of a text-based dungeon crawling game, where lack of memory and comprehension caused the game to constantly shift in entertaining ways.

Like with so much generative AI, I'm afraid to be excited where this leads. Counterfeit games where the first several seconds of gameplay appear to be a new game, but then it messily devolves into minecraft? An "indispensable" tool that is worse and more expensive but somehow game designers are required to use it as a starting point except it's actually way more work because there isn't even a game engine?
Anyways, at the moment you can play this still-weird-enough-to-be-kinda-fun game here!